
こんにちは。
本日はこちらのWebサイトにお越しいただき、ありがとうございます。2023年3月ChatGPTが4.0が発表された約1年後の、2024年3月、ChatGPT(チャットGPT)4.0を超えると言われるClaude 3(クロード・スリー)というモデルが発表されました。


Googleもなんか出してるよね?
ついていけなーーい!!
これは初心者が生成AIを嫌いになってしまう、由々しき問題。ということで、何が起こっているのかを、早速、調べました。
- ChatGPT4.0 よりすごいというClaude 3が気になる
- そもそも、どう違うのかも分からない
- 結局、どれを選べばいいの?
はじめに
生成AIのモデル(ChatGPTとかClaude 3とかのこと)、を比べるのにあたって重要なワードが2つあります。
「LLM」と「トークン」
この2つについて理解することで、新しいモデルは何を競争しているのかがわかるようになります。
この投稿は初心者にとっては、ちょっと難しいのですが、頑張ってついてきて下さい!
LLM(大規模言語モデル)とは何か?

大規模言語モデル(Large Language Models)=頭文字をとってLLM
LLMとは、大規模な言語モデルLarge Language Modelsの頭文字です。たくさんのテキスト情報を学習して、言葉を使ったタスクを行うAI(人工知能)の一種です。
大規模な言語モデル・・・そもそも言語モデルって何?ですね。
言語モデルとは
LLMの話をする前に、「言語モデル」について説明します。
言語モデルというのは、人間が話したり書いたりする「言葉」や「文章」をもとに、単語の出現確率をモデル化する技術です。
このようなモデルは、インターネット上にある大量の記事、本、会話などから情報を学び、それを元に新しい文章を作ったり、質問に答えたりすることができます。
【例えば】「ゴッホ」という言葉に続く言葉を推測します。「ゴッホ」→「作家」「ひまわり」は確率が高く、「ゴッホ」→「音楽家」は確率が低いというように予測することができます。
LLMは従来の言語モデルと比べて以下の3つの要素が大幅に強化されています。
- データ量:入力される情報量
- 計算量:コンピューターが処理する計算量
- パラメータ量:確率計算を行うための係数量
LLMの仕組み

ChatGPTのTはTransformerのTです。
STEP1 トークン化する

トークン化とは、テキストデータをコンピュータが理解しやすいように、文章を小さな言葉の塊であるトークンに分割する処理を指します。トークンとは、単語や句読点、記号など、テキストデータにおける最小単位の要素です。英語の場合、単語や句読点がトークンとなります。
英語のトークン化の例
文: “Today is a wonderful day.”
トークン化: “Today”, “is”, “a”, “wonderful”, “day”, “.”
日本語のトークン化の例
文:「今日はとてもいい天気ですね。」
トークン化:「今日」「は」「とても」「いい」「天気」「です」「ね」「。」
STEP2 エンコーディング処理
コンピュータはそのままでは解析できません。エンコーディング処理とは、トークン化されたデータを数値のベクトルに変換する処理を指します。
STEP3 ニューラルネットワークを通した学習
次に、ニューラルネットワークに入力します。ニューラルネットワークは、人間の脳の構造を模倣した数学的モデルで、大量のデータからパターンを学習する能力があります。トークン間の関係を学習し、どのように単語が組み合わされるか、どの文脈で使われるかを理解するための重要なプロセスです。
例えば、犬と猫の画像を見分けるというニューラルネットワークを作ってみます。
- まず、犬と猫の画像がたくさん入ったデータセットを用意する。
- ニューラルネットワークの中に、たくさんの小さなコンピュータを用意する。
- 犬と猫の画像を小さなコンピュータにどんどん見せていく。
- 小さなコンピュータは、犬と猫の画像の特徴を学習していく。
- 学習が終わったら、新しい犬と猫の画像を見せると、それが犬なのか猫なのかを判断できるようになる。
STEP4 コンテキスト(文脈)理解
コンテキストとは、何かを理解するために必要な背景情報や状況のことを指します。
コンテキストの種類:コンテキストには、様々な種類があります。
- 時間: いつの言葉なのか。
- 場所: どこでの言葉なのか。
- 人物: 誰が話しているのか。
- 話題: 何について話しているのか。
- 感情: 話している人の感情はどうか。
これらのコンテキスト情報を総合的に理解することで、より正確な判断ができるようになります。
その言葉や文章が使われた状況を知ることが大切
例えば、「暑い」という言葉。
- 真夏の日に外にいる場合は、「暑い」は「とても暑い」という意味になる。
- 冬の部屋にいる場合は、「暑い」は「少し暑い」という意味になる。
このように、同じ言葉でも、コンテキストによって意味が変わってきます。
このように、LLMは、文章を理解したり作ったりする力が非常に強いため、人と自然に会話ができるほか、作文の助けになったり、新しい物語を作ったりすることもできます。それで、人々が情報を得たり、学習したりする手助けをするわけです。

トークン数の競争
トークン数とは
先ほど出てきましたが、トークンは、言語モデルが学習または処理できる語彙の単位のこと。トークン数とは、その数を指します。
言語モデルが持つトークン数が多いほど、より多くの語彙や文脈をカバーでき、細かいニュアンスや複雑な文構造を理解する能力が向上します。


トークン数が多いことのメリット・デメリット
メリット:多くの情報を得ることができる
- 幅広い知識と表現力: 多くの書籍や論文などの文章を読み込むことで、幅広い知識と表現力を獲得することができます。これは、より高度な情報収集や文章生成、会話などに役立ちます。
- より精度の高い情報: より多くの情報に触れることで、世界に対する理解が深まり、より精度の高い情報提供が可能になります。
- 新しい知識への適応力: 新しい情報や知識を学習する能力が高くなり、常に最新の情報を取り入れることができます。
デメリット:処理速度の低下、電力消費の増加、過学習のリスク
- 処理速度の低下: トークン数が多いモデルは、処理する情報量が多いため、処理速度が遅くなる傾向があります。
- 計算量の増加: 膨大なデータを学習させるために、多くの計算量が必要となります。これは、電力消費やコスト増加につながります。
- 過学習のリスク: 大量のデータで学習させると、モデルは学習データの特徴に固執し、新しい状況への適応能力が低下する可能性があります。学習データに含まれる偏見や誤情報を学習してしまう可能性があると言われています。
トークン数の多いモデルは、ユーザーのニーズを満たす可能性が高いと考えられています。そのため、各サービスは差別化するために、高性能なモデルを開発が激化しています。
ただ、実際には、トークン数の増加だけでは性能向上は保証されません。各サービスは、トークン数の増加と同時に、処理速度の向上、電力消費の削減、過学習のリスクの低減などの課題を克服していく必要があります。
また、トークン数以外の要素も重要です。例えば、LLMの構造やデータの質なども、サービスの性能に大きな影響を与えます。
大規模言語モデル (LLM) の能力を向上させる手法
大規模言語モデル (LLM) は、近年目覚ましい進歩を遂げ、様々なタスクで人間レベルの能力を発揮しています。しかし、LLMには限界もあり、それを克服するために、これから紹介するRAGとファインチューニングが必要となります。
RAG(Retrieval Augmented Generation)とは、
RAG は、Webサイトなどの外部知識源から情報を組み込むことで、LLMに最新の情報や 専門的な知識を与えることができます。
例えば
- ニュース記事や論文などの文書データから情報を検索して、質問に答えるチャットボットの開発
- 辞書や百科事典などの知識ベースから情報を検索して、用語解説を行うシステムの開発
但し、課題として、検索結果の質によって、回答の質が左右される。外部知識源へのアクセスに時間がかかる場合がある。倫理的な問題 (偏見、差別など) への配慮が必要などの問題点が指摘されています。
ファインチューニングとは
ファインチューニングは、LLMを特定のタスクやドメインに特化させることで、LLMの精度を向上させることができます。これにより、LLMは限られたデータで学習できるようになり、 新しい知識を学習しやすくなります。
既存の学習済みのモデルに、特定の領域に関する追加学習を行わせる方法です。
例えば
ファインチューニングとは公開されている学習済のモデルに、独自のデータを追加で学習させ、新たな知識を蓄えたモデルを作り出す技術。
公開されている学習済みのモデルに、社内文書や顧客データなどの独自のデータを追加で学習させることで、LLMは企業特有の知識やノウハウを習得し、高度なタスクを実行できるようになります。

ようやく本題、Claude 3ってなに?
 Claude3(クロード・スリー)は、Anthropic(アンソロピック)提供する、大規模言語モデル(LLM)です。Anthropicには、経営理念の「安全性に重点を置いた設計」というのも注目した、Googleが巨額の出資をしたため、Google AIが使われています。
Claude3(クロード・スリー)は、Anthropic(アンソロピック)提供する、大規模言語モデル(LLM)です。Anthropicには、経営理念の「安全性に重点を置いた設計」というのも注目した、Googleが巨額の出資をしたため、Google AIが使われています。
ネット情報によると日本語の処理能力に優れていて、感想文などを書かせると、ChatGPTよりも日本語らしい文章を出力するという感想が多く見られます。また、ChatGPTよりも多くのデータ量を解読できるとのことで、比べられることが多いですね。
ちなみに、女性デザイナーが設計しているため、他の生成AIと比べるとフォントも明朝体を使っているなど女性らしいデザインです。(好みがあると思いますが)
Anthropicによると、数値としてはGPT-4を上回っていると報告しています。
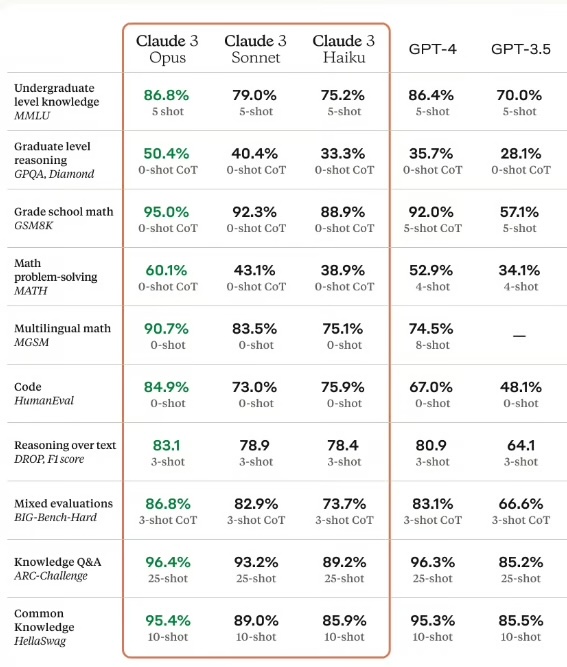
初心者が、2024年4月時点で比べるとしたら
主なサービスである、Claude、Gemini、ChatGPT、Bing AIの特徴は以下の通り。
各サービスの特徴
- Claude Pro: Google AIが提供する最先端のAIモデル。Google 検索との統合やプライバシー保護機能など、他のサービスにはない独自機能を持つ。
- Gemini Pro: Google AIが提供する高性能なAIモデル。Google ドライブとの統合やプライバシー保護機能など、Claude Proと同様の機能を持つ。
- ChatGPT Plus: OpenAIが提供する高性能なAIモデル。オープンソースであるため、ユーザーが自由にカスタマイズや改良を行うことができる。
- Bing AI: Microsoftが提供する高性能なAIモデル。Bing 検索との統合など、Microsoft製品との連携が特徴。
どのサービスを選ぶべきか
どのサービスを選ぶべきかは、ユーザーのニーズや目的によって異なります。
- 最先端のAI技術を体験したい場合は、Claude Proがおすすめです。画像生成ができません。
- Google ドライブやGoogle 検索との連携を重視する場合は、Gemini Proがおすすめです。
- オープンソースのAPIで自由にカスタマイズしたい場合(GPTs機能)は、ChatGPT Plusがおすすめです。
- Microsoft製品との連携を重視する場合は、Bing AIがおすすめです。
まとめ
色々と増えてきたLLMサービスですが、「おすすめはこれ!」とは言い切れませんでした。
また、最近人気になりつつあるのが、perplexity(パープレキシティ)。こちらは、Open AIやMetaで人工知能の開発に携わっていた優秀な技術者などにより、ChatGPTの座を奪うべく開発が行われたそうです。質問や会話を投げかけた際、ChatGPTがあらかじめ収集・学習したデータを基に回答するのに対して、Perplexityはその場でウェブクローリングを行なって回答します(ネット検索をするということ)。
しかもperplexity(パープレキシティ)がすごいのは、有料版にすると、Claude3やChatGPT4を使えてしまうのです!
こちらは私がまだあまりわかってないので、近日中に、少し触ってから投稿します。
















